
这是一个比较细节的知识点,但必须要理解这个才能准确判断Oracle ADG的延迟情况。
以前做运维工作时,记得是要同时重点关注v$dataguard_stats视图中的几个字段的值,分别是:NAME、VALUE、TIME_COMPUTED、DATUM_TIME。
本文先不考虑v$dataguard_stats视图没有数值显示的特殊情况,只针对当v$dataguard_stats视图正常显示的情况,如何准确判断Oracle ADG的延迟情况。
其实绝大部分管理过ADG的同学都知道,要重点关注NAME列中的transport lag和apply lag,看这两项在VALUE列中的取值,如果都是0,那基本没问题。
经验多些的同学还会在此基础上多关注TIME_COMPUTED、DATUM_TIME这两列的时间,是否近乎相同,和系统时间有无差异。
曾经遇到有用户在巡检ADG延迟时,只简单关注了前者,看都是0就判断没问题,可实际情况已经有很大的gap,这就是没有同时关注TIME_COMPUTED、DATUM_TIME的结果。
而若只关注TIME_COMPUTED、DATUM_TIME,却忽略掉NAME列中的transport lag和apply lag取值,这样也同样会可能造成误判。
如果说给建议就是要都关注,当然,有经验的DBA还会各种查其他信息加以证明,但这也不在本文讨论范围。如果只谈v$dataguard_stats视图,很多用户心里是没底的,因为不清楚细节,为什么会有各种表现情况呢?
通过查阅官方文档,其实在这些字段的描述上也不够精确,容易造成误解。
所以,本文就构建这样的动手实验环境,来帮助大家通过上手实践来具体观察典型场景,加深理解。
场景1: TIME_COMPUTED、DATUM_TIME二者时间近似,且都随系统时间变化
这种情况,无法判定ADG是否延迟。
ADG的传输链路正常,但是ADG备库的MRP进程很可能出现问题,或者不是实时应用导致ADG延迟。
下面开始动手实践构造这类场景的测试用例:
MRP进程异常crash,这里使用kill进程的命令来模拟,一段时间后再去查看ADG延迟的情况:
PHYSICAL STANDBY @DB0913_DG -> SYS @CDB$ROOT> set time on
03:04:32 PHYSICAL STANDBY @DB0913_DG -> SYS @CDB$ROOT> @dg
SOURCE_DBID SOURCE_DB_UNIQU NAME VALUE UNIT TIME_COMPUTED DATUM_TIME CON_ID
----------- --------------- ---------------------- ---------------- ------------------------------ ------------------------------ ------------------------------ ----------
2984003235 DB0913_9df_iad transport lag +00 00:00:00 day(2) to second(0) interval 04/09/2024 03:04:35 04/09/2024 03:04:34 0
2984003235 DB0913_9df_iad apply lag +00 00:37:12 day(2) to second(0) interval 04/09/2024 03:04:35 04/09/2024 03:04:34 0
2984003235 DB0913_9df_iad apply finish time +00 00:00:03.330 day(2) to second(3) interval 04/09/2024 03:04:35 0
0 estimated startup time 12 second 04/09/2024 03:04:35 0

上面例子,TIME_COMPUTED、DATUM_TIME二者时间近似,且随系统时间变化,但是实际ADG已经有了37分钟的应用延迟,体现在apply lag值。
所以必须要结合去看NAME列中的transport lag和apply lag的取值才OK。
场景2: NAME列中的transport lag和apply lag均为0
这种情况,无法判定ADG是否延迟。
当主库的传输链路不再传输,比如defer掉链路,那么这两个时间开始出现差异,并逐渐变大,注意这个时候apply lag不再变化。
下面开始动手实践构造这类场景的测试用例:
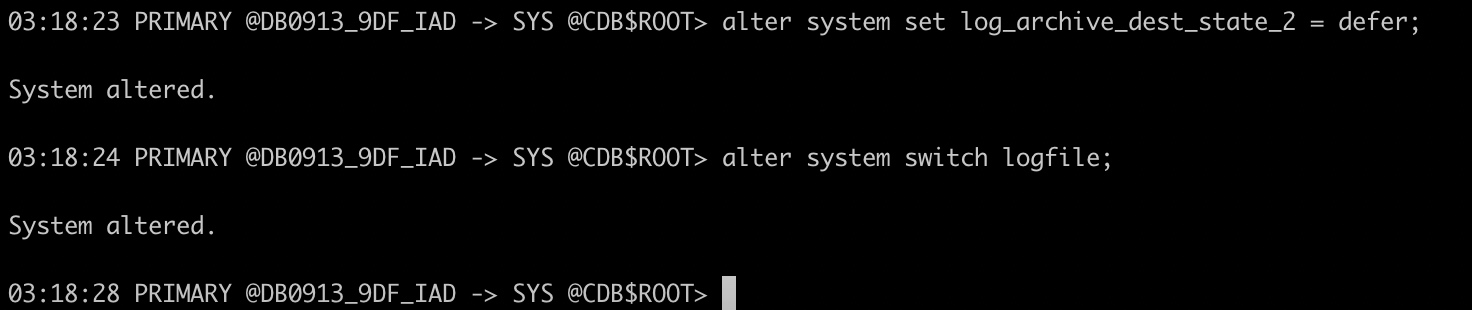
主库defer掉链路传输,然后切换下日志。
03:18:23 PRIMARY @DB0913_9DF_IAD -> SYS @CDB$ROOT> alter system set log_archive_dest_state_2 = defer;
System altered.
03:18:24 PRIMARY @DB0913_9DF_IAD -> SYS @CDB$ROOT> alter system switch logfile;
System altered.
备库查看ADG延迟情况:
03:24:32 PHYSICAL STANDBY @DB0913_DG -> SYS @CDB$ROOT> @dg
SOURCE_DBID SOURCE_DB_UNIQU NAME VALUE UNIT TIME_COMPUTED DATUM_TIME CON_ID
----------- --------------- ---------------------- ---------------- ------------------------------ ------------------------------ ------------------------------ ----------
2984003235 DB0913_9df_iad transport lag +00 00:00:00 day(2) to second(0) interval 04/09/2024 03:24:38 04/09/2024 03:18:27 0
2984003235 DB0913_9df_iad apply lag +00 00:00:00 day(2) to second(0) interval 04/09/2024 03:24:38 04/09/2024 03:18:27 0
2984003235 DB0913_9df_iad apply finish time +00 00:00:00.000 day(2) to second(3) interval 04/09/2024 03:24:38 0
0 estimated startup time 12 second 04/09/2024 03:24:38 0

虽然NAME列中的transport lag和apply lag均为0,但是TIME_COMPUTED – DATUM_TIME已经有数分钟的GAP,是不正常的。
所以监控,要考虑这种情况,比如发现 TIME_COMPUTED – DATUM_TIME > 10s 或者 1分钟,就需要告警关注。
而当主库链路正常时,DATUM_TIME会立马发生变化,重新与Time_computed近似:
03:24:38 PHYSICAL STANDBY @DB0913_DG -> SYS @CDB$ROOT> @dg
SOURCE_DBID SOURCE_DB_UNIQU NAME VALUE UNIT TIME_COMPUTED DATUM_TIME CON_ID
----------- --------------- ---------------------- ---------------- ------------------------------ ------------------------------ ------------------------------ ----------
2984003235 DB0913_9df_iad transport lag +00 00:07:46 day(2) to second(0) interval 04/09/2024 03:26:15 04/09/2024 03:26:14 0
2984003235 DB0913_9df_iad apply lag +00 00:07:46 day(2) to second(0) interval 04/09/2024 03:26:15 04/09/2024 03:26:14 0
2984003235 DB0913_9df_iad apply finish time +00 00:00:00.001 day(2) to second(3) interval 04/09/2024 03:26:15 0
0 estimated startup time 12 second 04/09/2024 03:26:15 0
03:26:15 PHYSICAL STANDBY @DB0913_DG -> SYS @CDB$ROOT> @dg
SOURCE_DBID SOURCE_DB_UNIQU NAME VALUE UNIT TIME_COMPUTED DATUM_TIME CON_ID
----------- --------------- ---------------------- ---------------- ------------------------------ ------------------------------ ------------------------------ ----------
2984003235 DB0913_9df_iad transport lag +00 00:00:00 day(2) to second(0) interval 04/09/2024 03:26:21 04/09/2024 03:26:19 0
2984003235 DB0913_9df_iad apply lag +00 00:00:00 day(2) to second(0) interval 04/09/2024 03:26:21 04/09/2024 03:26:19 0
2984003235 DB0913_9df_iad apply finish time +00 00:00:00.000 day(2) to second(3) interval 04/09/2024 03:26:21 0
0 estimated startup time 12 second 04/09/2024 03:26:21 0
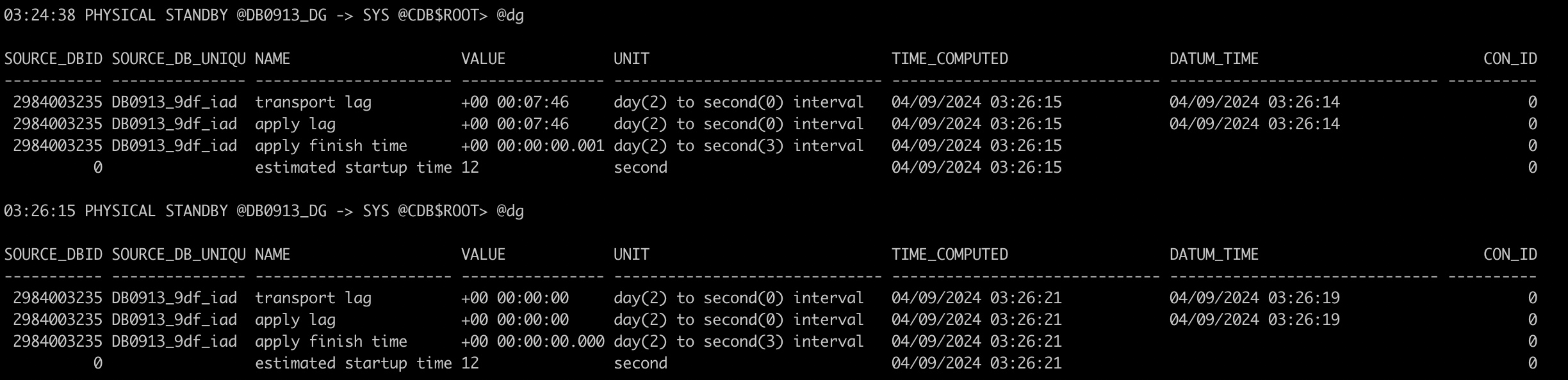
这里面还有个细节,当DATUM_TIME恢复正常后,里面会监测到真实的lag,然后开始应用,最终真正追平。
场景3: TIME_COMPUTED、DATUM_TIME二者时间近似,且都随系统时间变化,NAME列中的transport lag和apply lag均为0
TIME_COMPUTED、DATUM_TIME二者时间大概有1~2s的差值,随着系统时间不断更新。
NAME列中的transport lag和apply lag均为0。
这种情况,ADG正常,还是有1~2秒的延迟?
是正常的,这一点其实可以通过反证,比如将ADG设置为SYNC同步模式,TIME_COMPUTED、DATUM_TIME二者时间依然会有1~2s的差值,而此时机制是强同步的。
--ASYNC
alter system set log_archive_dest_2='SERVICE=DB0913_dg VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=DB0913_dg';
--SYNC
alter system set log_archive_dest_2='SERVICE=DB0913_dg SYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=DB0913_dg';
最后我们来看下官方文档对这些指标的权威解释:
V$DATAGUARD_STATS displays information about Oracle Data Guard metrics when queried on a standby database. No rows are returned when queried on a primary database.
对于NAME列的解释:
Name of the metric:
APPLY FINISH TIME - An estimate of the time needed to apply all received, but unapplied redo from the primary database. If there are one or more redo gaps on the standby database, an estimate of the time needed to apply all received, but unapplied redo up to the end of the last archived redo log before the beginning of the earliest redo gap.
APPLY LAG - Apply lag is a measure of the degree to which the data in a standby database lags behind the data in the primary database, due to delays in propagating and applying redo to the standby database. This value is relevent only to the applying instance.
TRANSPORT LAG - Transport lag is a measure of the degree to which the transport of redo to the standby database lags behind the generation of redo on the primary database. If there are one or more redo gaps on the standby database, the transport lag is calculated as if no redo has been received after the beginning of the earliest redo gap.
ESTIMATED STARTUP TIME - An estimate of the time needed to start and open the database.
可以看到,APPLY LAG是衡量备数据库中数据相对于主数据库的滞后程度。
TRANSPORT LAG是衡量将redo传输到备用数据库的延迟程度。
对于TIME_COMPUTED列的解释:
TIME_COMPUTED
Local time at the standby database when the metric was computed
TIME_COMPUTED是计算指标时备用数据库的本地时间。
对于DATUM_TIME列的解释:
DATUM_TIME
Local time at the standby database when the datum used to compute the metric was received
The APPLY LAG and TRANSPORT LAG metrics are computed based on data that is periodically received from the primary database. An unchanging value in this column across multiple queries indicates that the standby database is not receiving data from the primary database.
DATUM_TIME是接收到用于计算指标的数据时备用数据库的本地时间。
APPLY LAG和指标TRANSPORT LAG是根据从主数据库定期接收的数据计算的。如果该列中的值在多个查询中保持不变,则表示备用数据库未从主数据库接收数据。
怎么样?是不是单看官方文档的解释会很迷糊?
那就赶快动起手来,结合上面的实验亲自上手来验证观察,这样就能理解的更透彻,对判断DataGuard的延迟得心应手。
