
本篇文章素材来源于某银行系统的一次性能问题分析。
许久没写这种troubleshooting类型的技术文章了,因为曾在服务公司呆过多年,工作原因,这方面之前做的多,听的更多,导致已经达到在自己认知维度下的一个小瓶颈,纯技术型的问题,稍微常见的基本都遇到过,非常少见的也基本是bug类(软件缺陷只能通过补丁或一些workaround的方式绕过去),感觉实在是没啥可写的。
另外注意,我这里说的“常见”指的是所有客户群中相对常见,而对单个具体客户而言,就非常可能从没有见过,这也是纯甲方技术人员(这里的纯甲方是指毕业就在一个甲方呆着,只能看到自己公司系统运行情况)的局限性,在早些年时,一些行业前辈们还会建议新的技术从业者即使想去甲方,也要先在乙方吃几年苦,能多见一些场景,再去甲方,这样会有比较准确的判断力,不至于轻易被乙方忽悠,也不会瞎挑毛病挑不到点子上让人鄙视。
前些日子有客户遇到问题,申请出差过去现场帮客户分析解决了,这个分析过程还是有些意思的,但最终结论简单来说就是DPR(直接路径读)问题,定位那一刻就觉得没啥可写的了,相关文章也太多了,今天突然想换个思路,看能否以故事线的方式来呈现这个问题,并解释所有技术细节,试图能够让所有人(包括技术小白)都能看得懂,所有用户相关信息均已做遮蔽处理。
首先你要忘掉这是个DPR的问题,让我们一起体会下这个分析问题的历程。
起初是被同事叫来帮忙一起分析客户问题,搞了一个微信群,客户先发了一些所谓异常时间的AWR、ASH、ADDM报告。
说明环境是普通X86服务器上的一套Oracle RAC数据库,版本是11.2.0.4,有应用补丁,触发BUG风险相对较低。嗯,还是要强调下,这里说的低只是说主观感觉上,因为11g已经摸爬滚打了那么多年,无数客户曾趟出的bug也都做了修复,遇到新bug的概率相对小而已,但并不是遇不到,一旦运气不好遇到就麻烦了,所以我们现在会强烈建议你升级到现有的LTS(长期支持版本)19c,可不要再用11g了。
这里提到非常有用的报告:
- AWR(Automatic Workload Repository)
- ASH(Active Session History)
- ADDM(Automatic Database Diagnostic Monitor)
其中ADDM相对用的少,它可以自动分析 AWR 中的性能数据,识别潜在的性能问题,并生成相应的建议报告。对于复杂问题可能不够准确,但至少也能给我们提供一个思路。
AWR可以记录某个时段下的真实负载情况,ASH可以在某个时段下看到是哪些会话在运行,非常好用,对等待事件的细致划分程度,也是其他数据库梦寐以求的东西。
和应用配合明确这个业务感知慢的SQL是否是AWR中显示的Top SQL,同时明确对应的具体sql_id,开始深入分析。
起初明确的sql_id,有一个对应的是一个存储过程,但此时没有进一步去查。
因为另外一个sql_id被认为更值得关注,这是一条简单的SQL,查询一个分区表,谓词条件只有一个定位到某一天的日期,该表是按月分区的。该SQL奇怪是正常的时候1分钟以内完成,异常的时候要接近10分钟完成,前者客户认为正常可接受,后者认为无法接受。
同样的SQL,查询不同日期,效率差距如此明显,另外客户反馈每天数据量基本相当,并没有数量级的差异。
此时最先想要排查的是是否有不同的执行计划?
可结果并不是,执行计划虽然是全表扫,但是前后并没有任何变化。
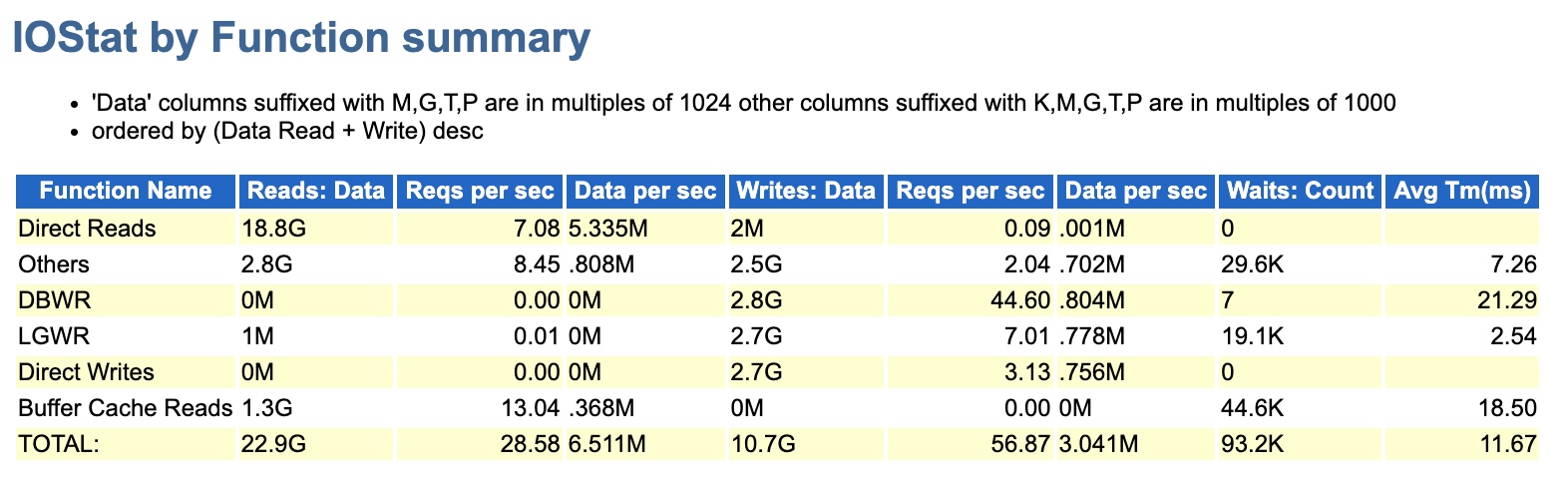
当时给的AWR中,我也看了IO部分,但只有3.3G的量级,感觉影响并不大,就忽略掉了。
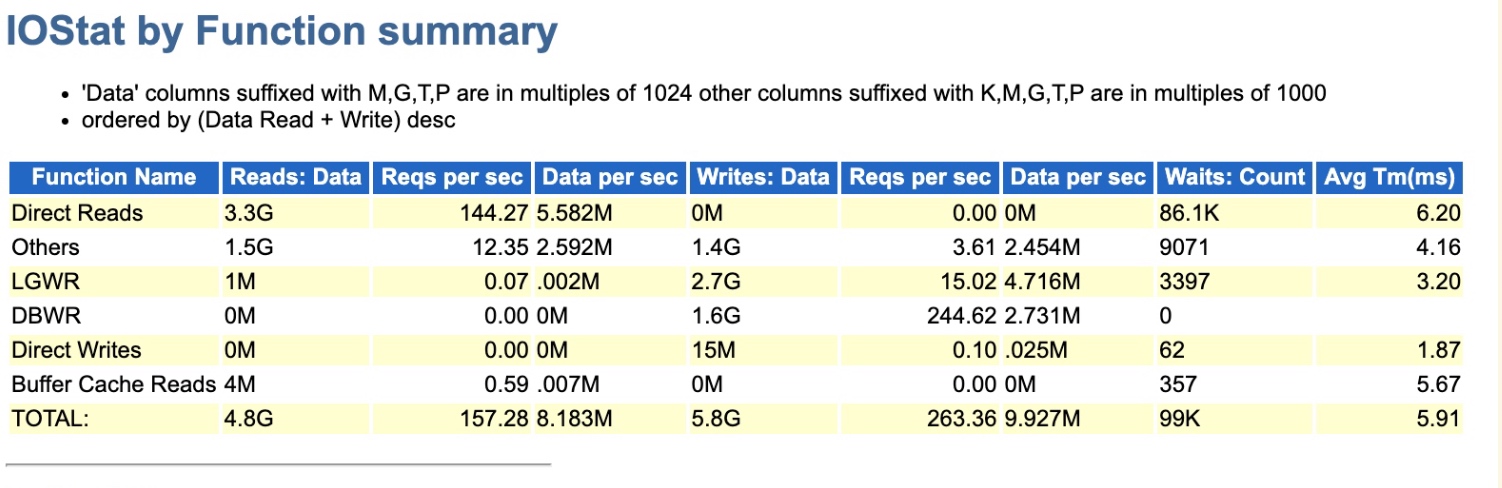
后来去现场,实际动手分析发现,其实故障时刻远没有之前的AWR报告那样轻描淡写,重新收集后续故障时刻的AWR(1小时间隔)可以看到此时的DPR非常显著,达到了314G+,要是之前做紧急救援服务,看到这就已经结束了,直接凭借经验断定,DPR禁用掉再看效果。因为再慢的话,会影响其他客户问题的处理进度。
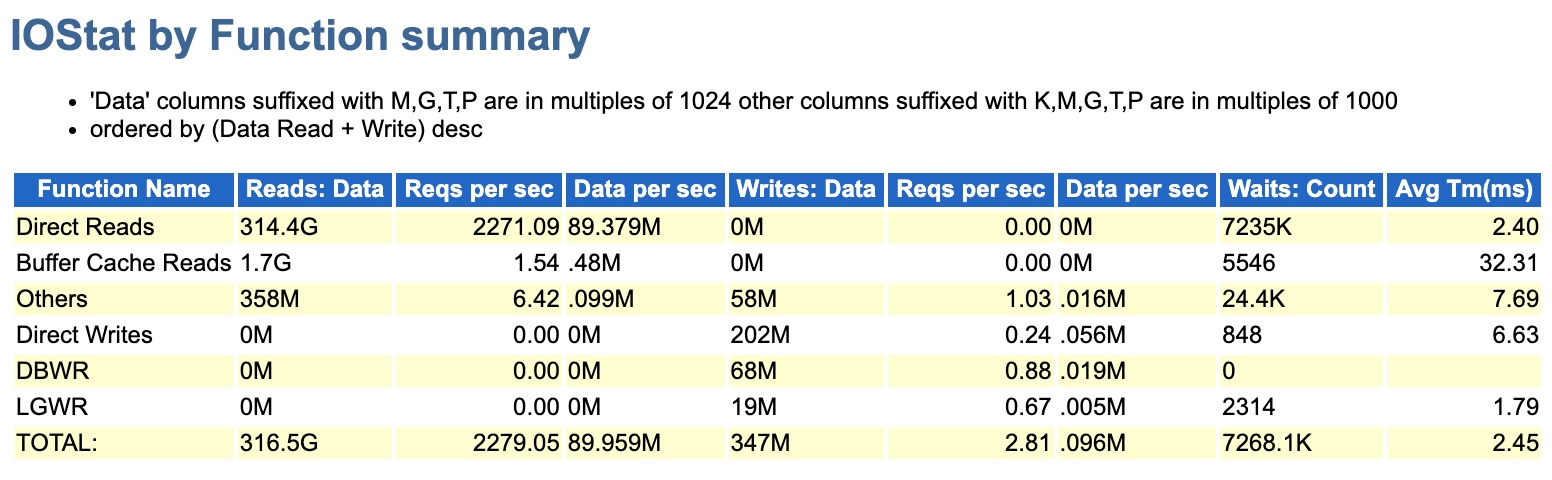
其实那种凭借历史经验直接判断问题虽然有很快很厉害的感觉,但却是不严谨的,现在我们要进一步确认细节,确认是否是这个问题。既然是DPR,再看TOP SQL中通过Reads的排序,发现Top 2都值得关注,因为物理读几千万,和后面SQL存在数量级上的差异:
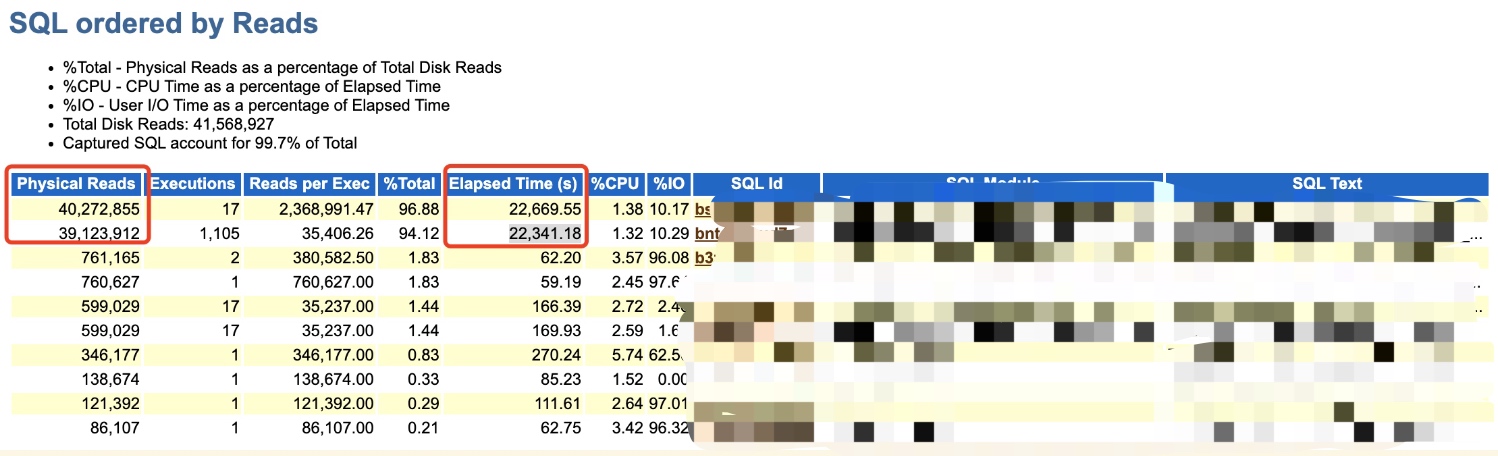
Top 1是一个存储过程,Top 2是一个SQL,经确认这个SQL也是存储过程之内的一条SQL,但是并不是之前我们分析的那条SQL,说明之前提供的方向有一定错误。这也说明这个Top 2才是问题根本。
同时配合ASH也可以看到的确就是这SQL引发的DPR,导致性能严重下降。
到这里就可以相对稳妥的结案了。
可是呢,好巧不巧的在我介入分析之前,故障后应用侧试着调整了索引,变得可接受,但后来又变差,又重建索引,又重启了数据库,一系列操作,导致业务表现变好了,但是问题到底有没有解决,有没有隐患,都未可知。解释这一系列的问题,还需要继续深入分析更多的数据,找到证据证明这一切的因果。
首先,看看所谓变好的时刻,拿到AWR可以看到确实是没有千万级别的物理读了,而且问题SQL都不在TOP SQL中了。
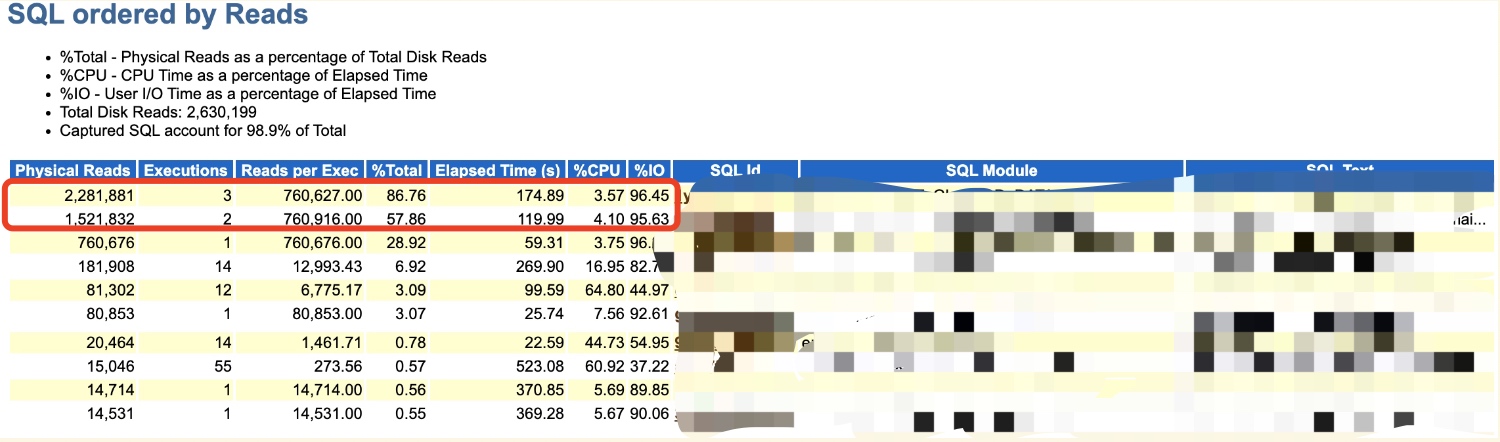
而DPR呢,期间也下降到了18G的情况,比300多G那会儿是好太多了。也说明为什么最早3G多我会忽略,因为真的太小没太大影响,也不值当考虑。
下面来看这一系列的问题:
-
1.调整了索引,变得可接受
是因为有索引后,执行计划走了索引,没有引发这个SQL的DPR,所以效果变好。 -
2.但后来又变差
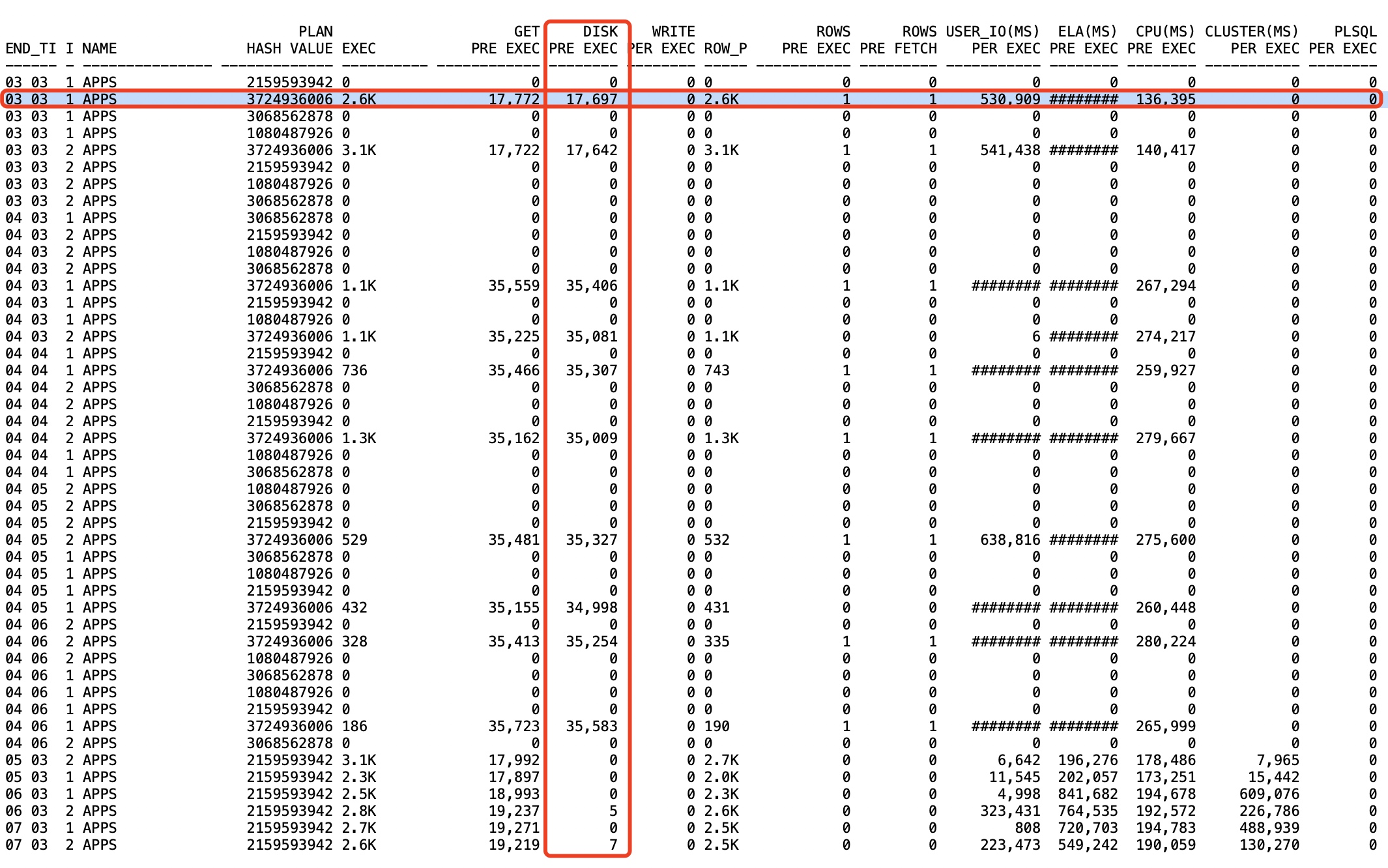
这里是因为执行计划又走错了,走回全表扫导致引发DPR。
看下面这个查询结果,我们可以看到在变差的时段,全都是走了全表扫的372开头(PLAN HASH VALUE)的这个执行计划,而这个执行计划是DPR的方式,所以,虽然执行数千次,但是每次平均的DISK读都相当。
- 3.又重建索引,又重启了数据库
这个操作其实就是碰巧了,重启后走了好的执行计划,但以后不稳定的因素依然存在。
可是现在要如何来做呢?
其实在这个客户的系统情况下,讨论后还是建议要禁用DPR,因为DPR的设计初衷是,让那些偶尔访问的大表可以不对buffer cache产生大冲击,而默认这类大表操作次数是很小的,所以是好的设计。
但这个案例中,表不会特别大,也就是刚好超过“_small_table_threshold”的设置,但是却访问数千次,走DPR是一种灾难。
关闭Oracle 11g的DPR特性可参考:
https://www.cnblogs.com/jyzhao/p/6724299.html
简单来说,数据库不重启的话,就动态去设置这个隐藏参数:“_serial_direct_read”,相关操作参考:
--查询隐藏参数设置情况:
SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describ
FROM SYS.x$ksppi x, SYS.x$ksppcv y
WHERE x.inst_id = USERENV ('Instance')
AND y.inst_id = USERENV ('Instance')
AND x.indx = y.indx
AND (x.ksppinm ='_small_table_threshold' or x.ksppinm='_serial_direct_read');
--setting:设置隐藏参数为NEVER
alter system set "_serial_direct_read"=never;
--rollback:设置隐藏参数为默认值
alter system set "_serial_direct_read"=auto;
alter system reset "_serial_direct_read";
--永久生效:
SQL> show parameter event
SQL> alter system set event='10949 trace name context forever,level 1' sid='*' scope=spfile;
--其实也可以session级别更改,影响更小:
alter session set "_serial_direct_read"=never;
回顾下最初问题:同样的SQL,怎么突然就慢了?
执行计划没变时,是因为DPR这个特性导致,新分区虽然数据量和历史相当,但blocks却明显增多,超过了小表阈值。
后续建了索引变好,后又变坏,是因为有时候选错执行计划导致又走了全表扫又触发了DPR。
其实如果再想深究探索,还有好多可以思考的,比如,为什么新分区虽然数据量和历史相当,但blocks却明显增多?比如为何建立索引后有时又选错执行计划等等。只要你愿意,就又能探索到好多知识,即便Oracle已经非常成熟,但Oracle DBA也同样可以做的有技术深度。
最后要说的是,任何隐藏参数都是不建议用户主动去设置的,DPR这个虽然在很多服务商都建议最佳实践中都关闭,但是真正正确的打开方式是,要分情况,要在厂商指导下进行操作。比如举个极端的例子,如果用户使用Exadata一体机,上来就把DRP给关了,那就有些暴殄天物了,即便不是一体机,也看你的系统实际情况来决定,有些特性其实还是很好的,只是特定的一些场景下不适用而已,不过要真正分的清说的明这些内容,就还是要修炼自己的内功的。
